Ankur Gupta

Senior Staff Technical Program Manager, AI Infrastructure @ LinkedIn
I am a Senior Staff Technical Program Manager in AI Infrastructure at LinkedIn, based in San Jose, California. For more than 15 years I have led large-scale enterprise and internet-scale infrastructure programs across global technology organizations, turning ambiguous, cross-organizational technical problems into reliable, measurable platforms.
My work sits at the intersection of program management, platform engineering, and AI infrastructure: GPU-accelerated inference systems, model deployment pipelines, company-wide reliability transformations, data center buildouts, and a first-of-its-kind hardware forecasting control plane. I specialize in the coordination patterns, governance frameworks, and execution discipline required to align dozens of engineering teams and ship dependable systems at scale.
I am an IEEE Senior Member, and I write here at The Reliability Brief about the things I have learned along the way.
15+Years of experience225Teams coordinated (SRE3)4.4×GPU efficiency gain~$20MGPU CapEx avoided
What I do
As a Senior Staff TPM in AI Infrastructure, I lead company-critical programs across model deployment, serving, reliability, and capacity planning, enabling production machine learning for LinkedIn products including Ads, Feed, Search, Premium, and Trust. Day to day, I:
- Lead complex cross-organizational technical initiatives spanning platform engineers, ML engineers, and site reliability teams.
- Translate ambiguous technical problems into executable roadmaps with clear SLOs, OKRs, and delivery milestones.
- Partner with senior engineers, architects, and executives to influence system architecture, rollout strategy, and long-term infrastructure direction.
- Drive deployment velocity and reliability, infrastructure efficiency, and multi-million-dollar cost optimization.
Experience
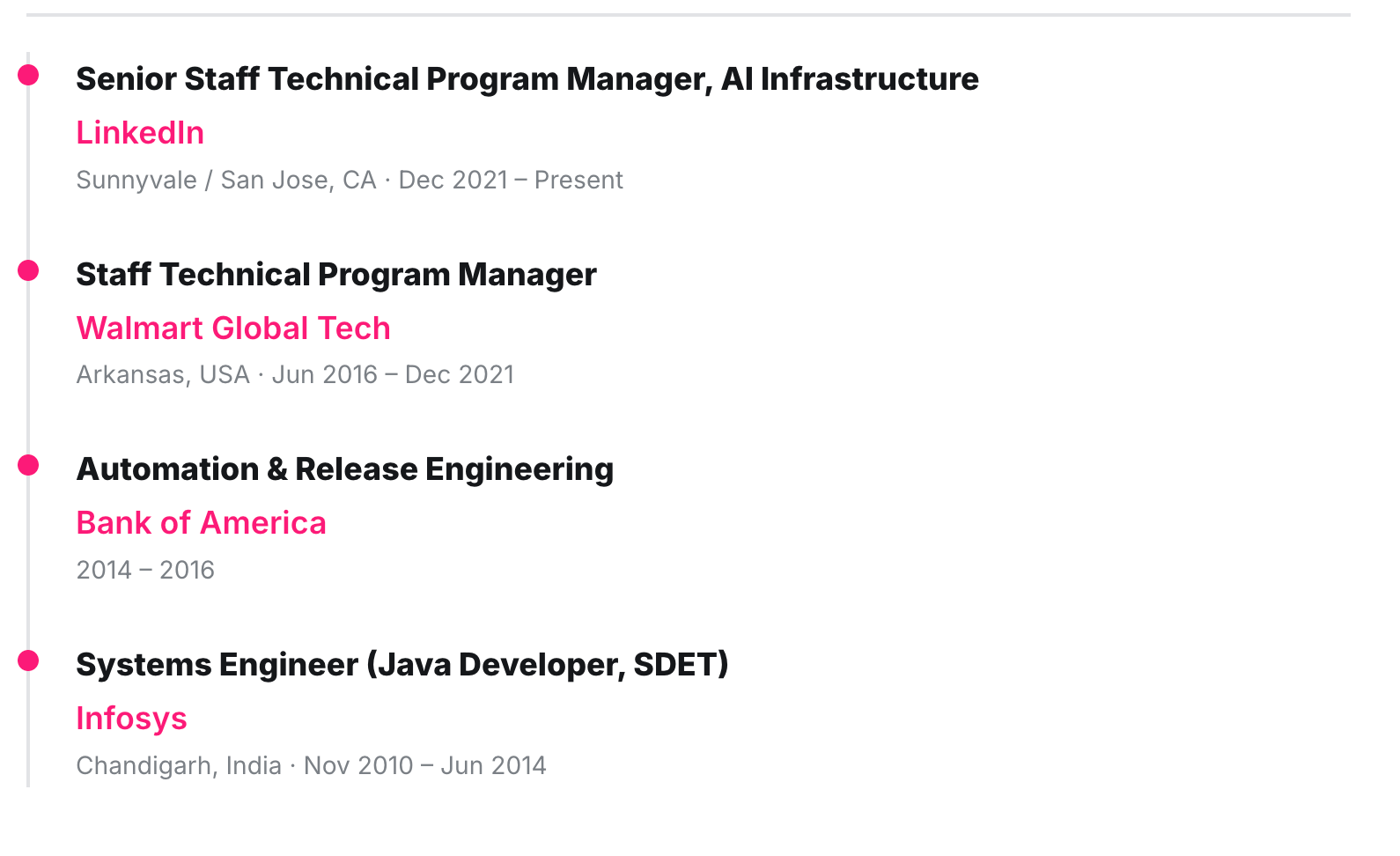
Selected programs
AI Infrastructure & GPU Efficiency — LinkedIn (2023–Present). Built and operationalized AI infrastructure platforms enabling reliable model deployment across Ads, Feed, Search, Premium, and Trust. Ramped the Ads DCNv2 model using a disaggregated serving architecture, improving throughput from ~90 QPS to ~400 QPS per A100 GPU at 50ms p99 latency (≈4.4× efficiency, ~$20M estimated GPU CapEx savings, 17% CTR uplift). Raised model deployment success from ~60% to over 99% and cut deployment time from days tohours.
Infrastructure Forecasting & Capacity Planning — LinkedIn (2023–2025). Designed and led a centralized forecasting control plane replacing spreadsheet-based planning across 22 infrastructure teams. Eliminated 10,000+ hours of manual effort and reduced projected infrastructure demand by ~$350M (FY24) and ~$480M (FY25).
SRE3 Reliability Transformation — LinkedIn (2021–2023). Led the reliability operating-model transformation across 225 engineering and SRE teams covering ~1,400 production services. Delivered a 61% reduction in incident mitigation time, 33% faster detection, 60% fewer traffic-validation incidents, and ~$15M in cost avoidance.
SAP Cloud Migration & Modernization — Walmart Global Tech (2017–2020). Led enterprise SAP modernization across 350+ applications, 40 teams, and 11 countries, migrating 2,000+ servers and ~5PB of data to Microsoft Azure. Delivered ~$12M in savings and 84% faster deployments.
Education
- M.S., Information Management (Data Science) — Syracuse University, School of Information Studies (2014–2016) · GPA 3.94/4.0
- Certificate of Advanced Studies, Data Science — Syracuse University (2016)
- B.E., Computer Science & Engineering — Maharshi Dayanand University, India (2006–2010)
Awards & recognition
- Mountain Mover Award — LinkedIn (Dec 2023)
- SRE TPM Excellence Award — LinkedIn (Jul 2023)
- Associate of the Quarter, SAP Digital Solutions — Walmart Global Tech (Oct 2019)
- Global Recognition Award — Bank of America (Aug 2015)
- INSTA Award — Infosys (Mar 2014)
- Most Valuable Player (MVP) — Infosys (Jan 2012)
What I write about
I write about the craft of technical program management (leading without authority, managing risk, running large programs), the engineering problems I have lived through (reliability, incidents, AI/ML platforms, infrastructure at scale), and system design from first principles. My goal is to make hard-won, real-world lessons useful to other practitioners.
Most large programs do not fail because nobody saw the problems coming. They fail because the problems were visible and never acted on. My job is to build the systems that force action.
Publications & writing
- PM, TPM, and EM: A Practical Framework for Technical Leadership Roles — Stackademic / Medium
- IEEE Computer Society — technical articles on AI infrastructure, forecasting, and reliability engineering (ongoing)
- ORCID: 0009-0006-4758-4973
- Google Scholar: profile
- Web of Science ResearcherID: PLD-1424-2026
Talks, videos & podcasts
- BSmart — Manager's Mantra: How automation is changing managerial roles — a conversation on automation, evolving cloud strategies, their impact on managerial roles, and career advice.
More talks and podcast appearances coming soon.